

Fabric brings you many different technologies and concepts to mix and match so that you can find the most optimised solution for your data requirements. One of those concepts is the Lakehouse, and we'll be looking into how we can build a proper one in Fabric using the Medallion Architecture.
As we've covered "What is Lakehouse?" in a previous article and the Medallion Architecture in the "Designing Fabric Workspaces" post, I won't go into too much detail here. But to recap, Medallion Architecture stands on the promise of splitting your data into multiple layers with different responsibilities. If interested in reading further, you can read Databricks' Medallion Architecture article.
This article will demonstrate implementing the best practice for Medallion Architecture in Fabric, and although we'll walk through the steps, we won't build the actual pipelines here. Instead, I'll show you how everything will be connected to the Lakehouse in four steps:
- Step 1: Designing the Lake
- Step 2: Establishing the Tables
- Step 3: Building the Pipelines
- Step 4: Putting it all together
We will cover the overnight data-pulling scenario with Pipelines and Dataflows in this article, but future articles will be on Streaming datasets and connecting to other Azure data resources.
Step 1: Designing The Lake
Before going into what we're going to use to process the data, let's define our zones/layers in our OneLake:
- Landing: A layer for incoming data to arrive, ready to be picked up by our Lakehouse ingestion process. Data is kept in the original file format, with a folder structure reflecting arrival metadata. The data is kept here temporarily and deleted after the Lakehouse ingests it.
- Bronze/Raw: A layer for incoming data to be kept and archived for access. You keep the data as it comes to only store it in Delta format and in a hierarchy to access them easily (most commonly, date of arrival and data type)
- Silver/Trusted: Raw data is translated into a more standardised format. You can split a single raw file into multiple files/tables to create a normalised relationship, or you can put together numerous raw files into a single table.
- Gold/Curated: For business-level aggregations and analytics.
Each area would have their rules and own semantic structure for either arranging folders or partitioning the data kept in Delta files. Whilst Landing and Bronze would primarily focus on "Date of Arrival" for the data, so there could be a distinct line of what's been processed and what isn't yet, Silver and Gold would have a partitioning based on the business rules of the data. Here's how the folder breakdown/partitioning would look like on each layer:
- Landing:
- Partitions: Date of arrival, system name, dataset
- Path Format: /landing/2023-08-24/ordersystem/orders.csv
- Bronze:
- Partitions: Date of arrival, system name, dataset
- Path Format: /bronze/ordersystem/orders/year=2023/month=08/day=24/
- Silver:
- Partitions: system name, dataset, order date
- Path Format: /silver/ordersystem/orders/year=2023/month=08/day=24/
- Gold:
- Partitions: Data product name, dataset
- Path Format:
- /gold/sales/sales-leaderboard/year=2023/month=08/
- /gold/customer-insights/customers-by-postcode/postcode=SW9/
The purpose of this segregation is simple: Defining a clear path for the data flow and making the intermediary steps available for unlocking further analytics capabilities. Whilst the endgame here is to carry the data into the gold layer and gain insights from it, we're making the Bronze and Silver available as separate layers so different pipelines can reuse them.
When applied to OneLake, the layers would look like below. I've chosen an Order System example for simplicity, and all layers are encapsulated within a single Lakehouse in a single Workspace. It can, of course, be done in many different ways.

The flow of the data is as follows:
- Order data lands in a CSV format in the Landing zone under the 'ordersystem' folder and a date folder under that. It is received daily as an overnight job (for simplicity of the example).
- When moved into the Bronze layer, the Order data is kept as a single 'orders' Delta file, but underneath, it is partitioned to include the Year, Month and Day values of DateOfArrival metadata. When the data is read from the Bronze layer, it's based on this DateOfArrival column. The data is continuously appended to the Bronze layer; even if there was a correction in an order from yesterday, we receive the same record with a different DateOfArrival here.
- The Silver layer is a normalised data layer, where we split the Orders data into 4 Delta files: Orders, Order Details, Customers, and Contact Details. The Silver layer data is kept merged, compared to Bronze and Landing, which are appended. That means when there's an update or delete, it's reflected in the Silver layer for that particular record. For our Orders, we'll be partitioning the data using OrderDate.
- The Gold layer is a business-aggregation layer, which means the data is collated from multiple Silver and Gold data sources into a business-insight-giving Gold dataset. The partitioning can differ from dataset to dataset. An example is whilst sales projections are partitioned using Year data, customers by postcode will use PostCode information (maybe the first part of the UK postcodes).
Step 2: Establishing The Tables
Whilst you can use Delta files directly in your pipeline and do not worry about SQL tables, a Data Lakehouse is an evolution of the Data Warehouse, inheriting specific capabilities. SQL tables are schema-controlled and easily discoverable, making their metadata and relationships readily available. SQL is a language invented for data manipulation and querying purposes, and many tools in the ecosystem can give you further value.
In Spark-based Lakehouse environments like Synapse Analytics and Fabric, the databases and tables are backed by Delta files you have on the lake. You can let Synapse/Fabric manage the data backed by tables for you (called Managed Tables), or you can point your tables to your existing Delta files. There are pros and cons to both approaches.
There are many different ways of designing your databases and tables, but for the sake of simplicity of the article, I kept it simple for the example's sake. Here's what our Order example would look like:
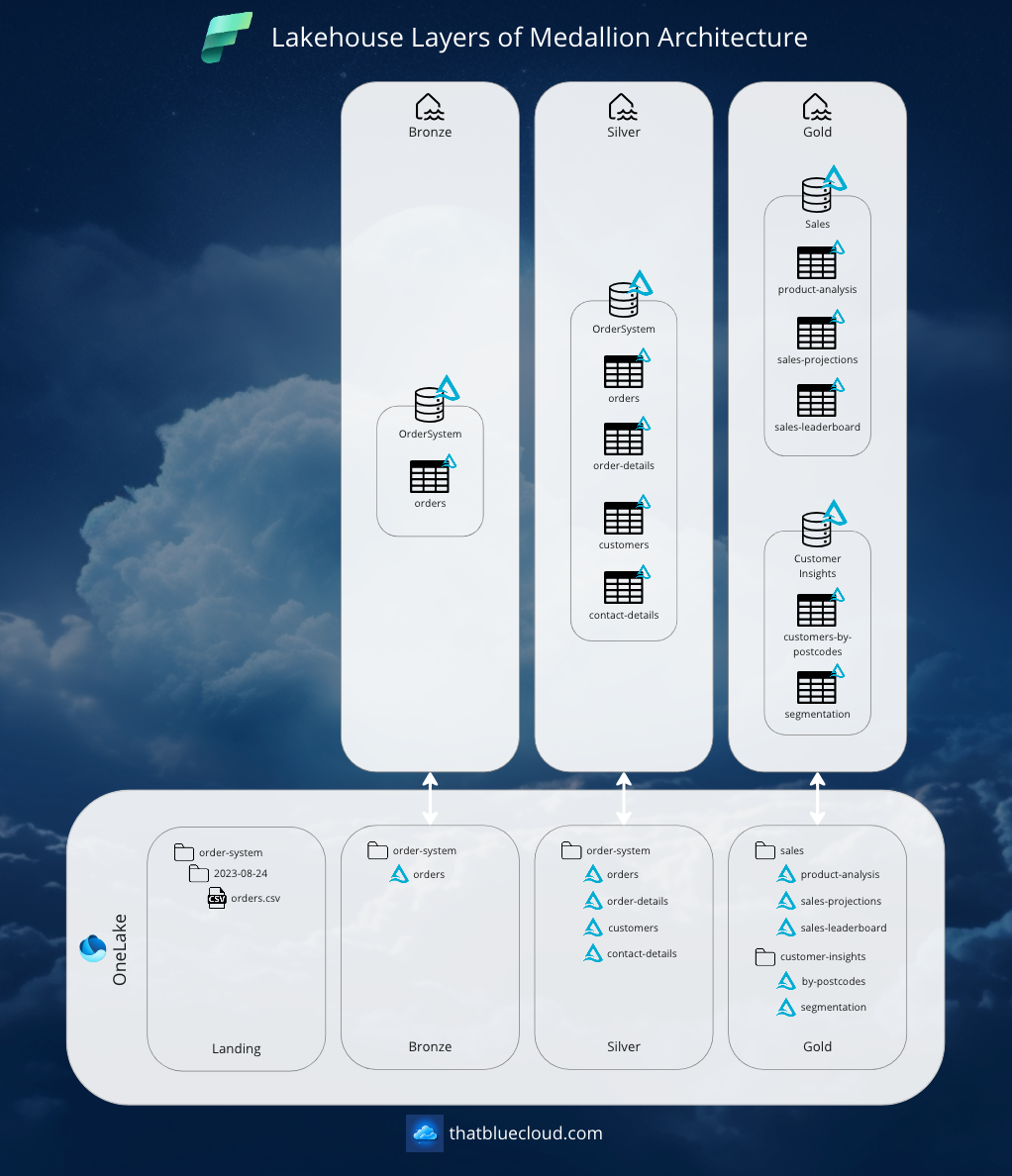
Although this is an example, I think it's best to talk through each of the database's and its tables' responsibilities so the purpose of each layer would be more clear:
- Bronze
- OrderSystem
- orders: Keeping the order data and itemised details in a denormalised way, repeating the orderNumber and order information for each product ordered.
- OrderSystem
- Silver
- OrderSystem
- orders: Keeping the order header information (date, number, delivery address, total amount, etc.)
- order-details: Keeping the itemised details (product name, amount, unit price, etc.)
- customers: Keeping customer information. This table is updated with every order received from the same CustomerId from the Bronze layer.
- contact-details: Keeping Customer's contact information (emails, phone numbers, addresses as rows). They are kept as updated as the Customer is updated on the source.
- OrderSystem
- Gold
- Sales: The database that keeps analytics for the Sales team.
- product-analysis: Analysing the trend of each product's orders on a month-by-month basis.
- sales-projections: Based on the product analysis, making order projections for the next 3, 6 and 12 months.
- sales-leaderboard: Keeping track of yearly total sales of each salesperson and branch taking orders.
- Customer Insights: The shared database across teams for Customer related insights.
- customers-by-postcode: Keeping analytics of each customer postcode zone and how many customers, to be compared later with branch-based geo-analysis.
- segmentation: To be used by marketing for audience creation, each Customer is segmented based on their history of purchases and the likelihood of purchasing in the next 1,2,3,6 and 12 months.
- Sales: The database that keeps analytics for the Sales team.
In terms of table relationships, here's how the tables in the Silver zone would look like:
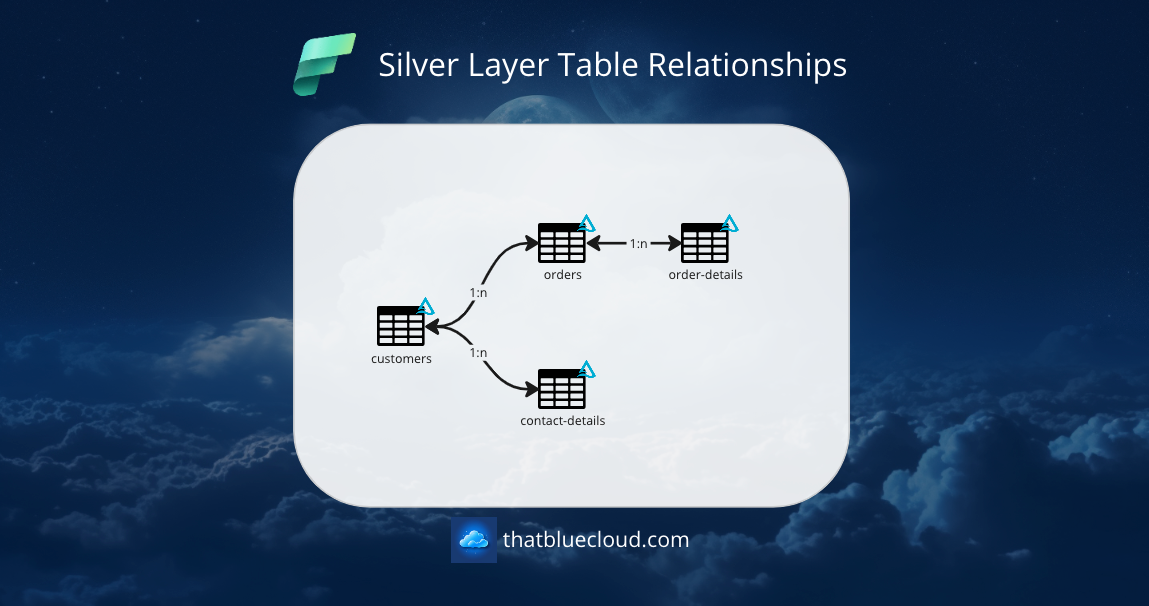
Step 3: Building The Pipelines
After our preparation, the next step is building our data pipelines and Dataflows to bring the data into our Lakehouse. Let's start with how the pipeline will look on the high level and then start talking about each step:
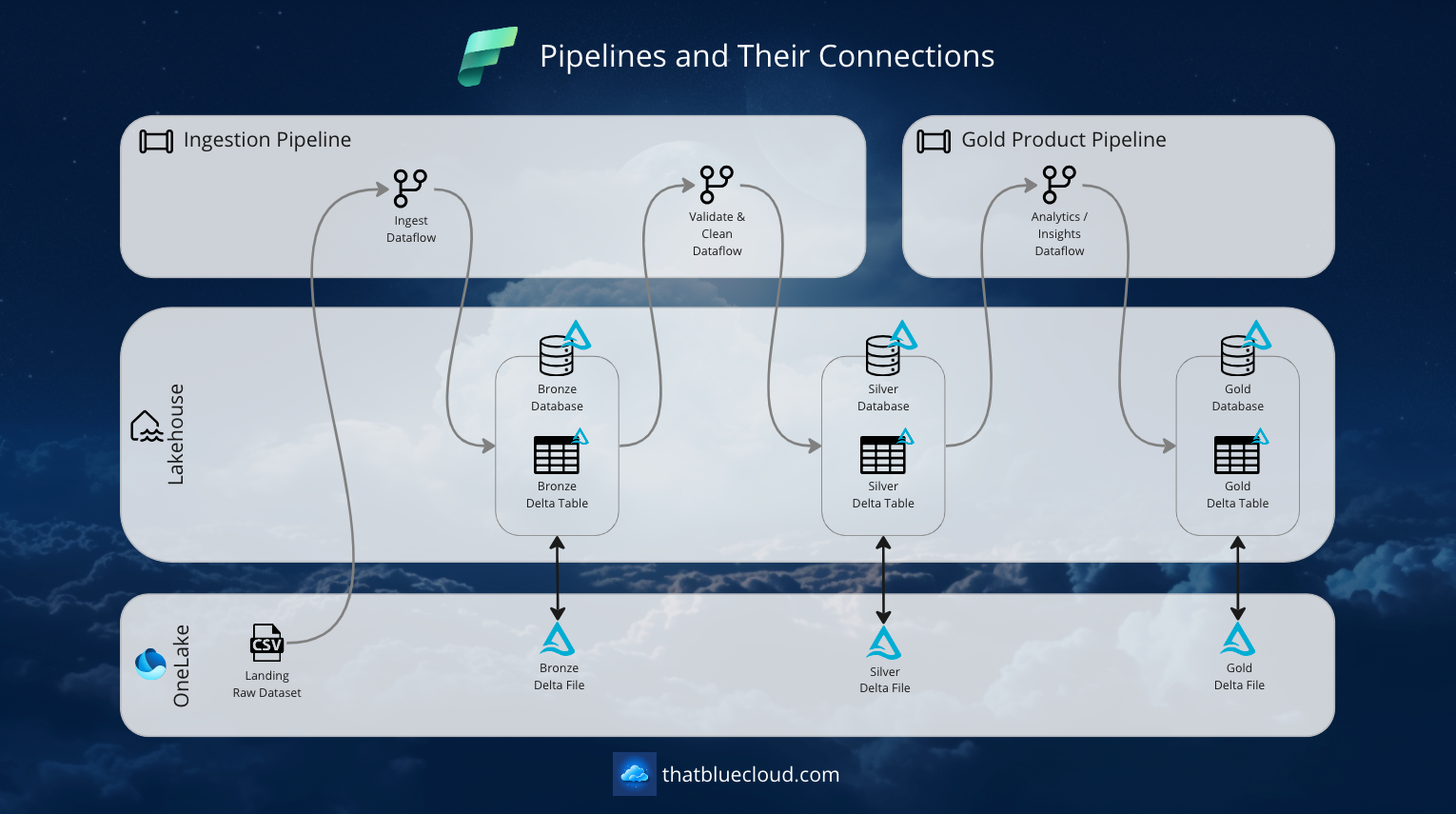
We have two types of pipelines in general.
Ingestion & Validation Pipelines
These pipelines are responsible for bringing the data into the Lakehouse Bronze zone, validating it, and pushing it into the Silver zone. Their responsibility is to create suitable Silver datasets for the consumption of Gold pipelines or other types of processes to consume source-based, normalised, quality-checked data.
We're extracting the Ingestion & Validation process into a separate pipeline instead of creating a single pipeline that would include Gold data processes to make the Silver dataset reusable. Instead of making an intermediary step for a single Gold pipeline, we're making Silver a product on its own so multiple consumers can consume it.

In our Orders example, we have a single Order Ingestion Pipeline, but we have two Gold pipelines using the Silver tables created by our pipeline. Here are our Ingest & Validate Pipelines:
- Order Ingest Pipeline: The Ingest & Validate Pipeline for our Orders dataset coming from the Order System. It runs daily, as our Order System only sends the data overnight. It has two dataflows:
- Ingest Dataflow: It receives the data from Landing, then loads it into the Bronze layer. It runs based on the date of arrival to read data from Landing. It always appends the data and doesn't update.
- Validate & Clean Dataflow: Loads the data from the Bronze layer based on the date of arrival, runs validations & data cleaning, then splits the data into four tables in the Silver layer. It reflects the changes from the Bronze layer onto the Silver data, meaning it can insert, update or delete records in the Silver layer.
Gold Product Pipelines
Responsible for using the Silver layer data, generating insights and analytics and fulfilling business requirements. Gold Products can be anything (a SQL database, a CSV file, a Lakehouse SQL Endpoint, a Power BI Report, etc.), but their real purpose is to generate value. Remember:
- Sales Reporting Pipeline: The Gold Product Pipeline for preparing analytics/insights by reading the order information from the Silver layer and then populating the Sales Gold Database.
- Analytics / Insights Dataflow: Slices and dices the data to achieve the business requirement and spits out into three different tables in the Gold database.
- Customer Insights Pipeline: The Gold Product Pipeline for preparing analytics/insights by reading the customer and order information from the Silver layer, then populating the Customer Insights Database.
- Analytics / Insights Dataflow: Slices and dices the data to achieve the business requirement and spits out into two different tables in the Gold database.
Putting It All Together
We've discussed the Pipelines, Dataflows, Lake Zones, file structures, partitions, etc. Now, it's time to put it all together. Let's see how the Lakehouse will look in the big picture:
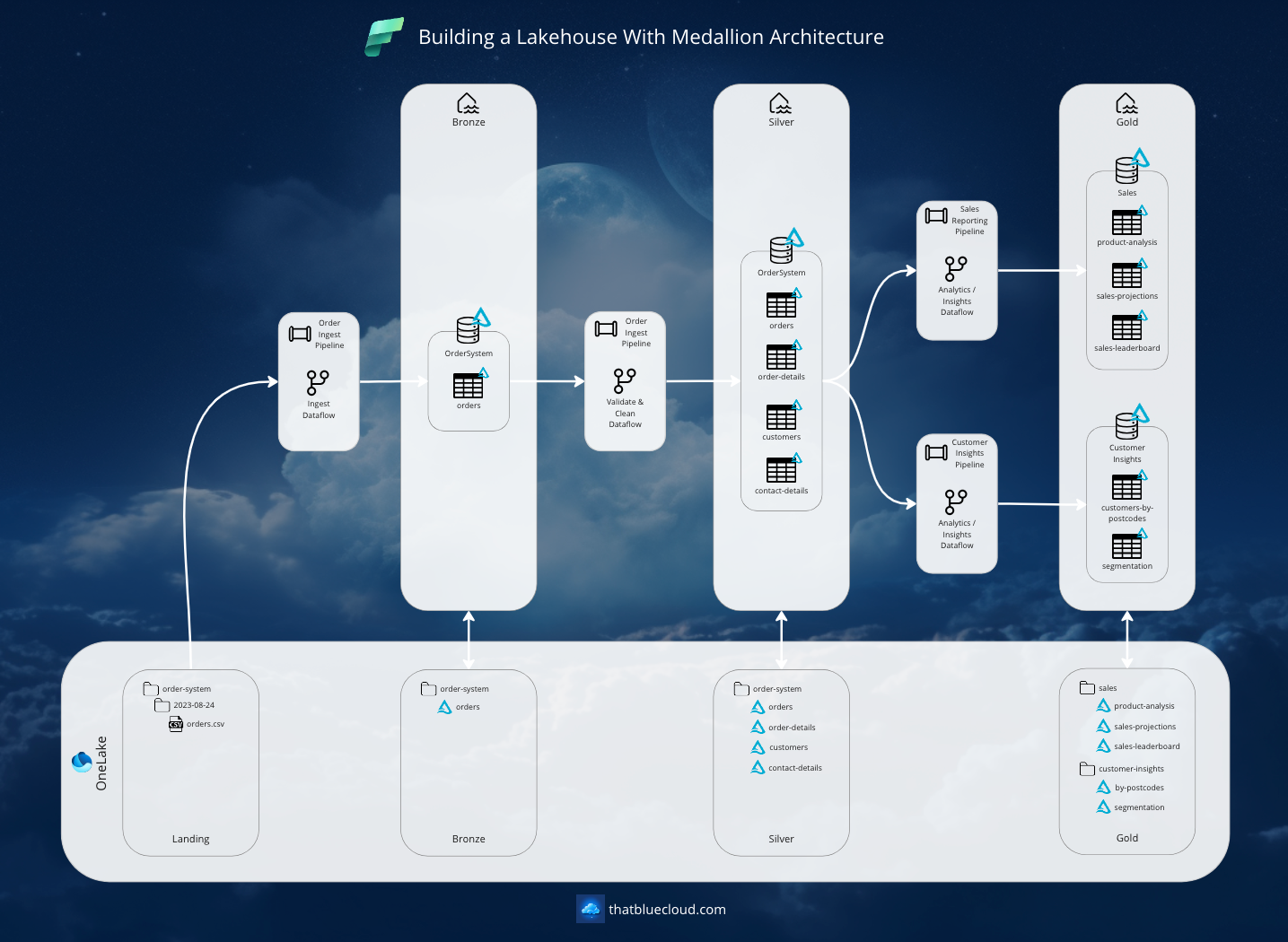
The data will land in the Landing zone, be carried into the Bronze and Silver layers, and then be converted into value in the Gold layer. While all this is to get to the Gold part, you can connect to Bronze and Silver from other apps or reports, like Machine Learning model training scenarios.
I hope this helps, and I will see you in the following article.
Further Reading
 Harun Legoz
Harun Legoz Harun Legoz
Harun Legoz
Remember to subscribe to our TBC Weekly newsletter! You'll get a summary of the latest articles from us and the Fabric and Azure communities.
