

Articles in this design series:
- 1 - Introduction
- 2 - High-Level Design
- 3 - Trusted Data Products
- 4 - Gold Data Products
- 5 - Benefits & Drawbacks
An automotive company's ecosystem is much larger than our defined universe, but the principle is the same on a bigger scale. We're trying to make the data available on our platform, and we have a few methods to access and retrieve the data:
- Scheduled: Includes scheduled data transfers like overnight, daily, weekly, etc., which can happen as a pull or push method.
- Event-Based: Executing data ingestion when the data is available and an event is received.
- Streaming: Includes near-realtime or realtime scenarios with large amounts of data constantly received from multiple sources.
In our Trusted Data Products, we will package the data coming from source systems into separate Fabric Workspaces, including the Bronze and Silver layers. This will allow us to reuse both datasets in multiple Gold product scenarios and ensure the data is protected with proper access controls. Fabric's item-level security currently doesn't cover every scenario, so whilst creating these sources as Lakehouses in a single Workspace is possible, it would get crowded very quickly with Pipelines and Dataflows, and the access management would be a living hell. Until there's a better approach, splitting into multiple Workspaces is better.
When ingesting data, we will focus on getting the data into the Landing area and then consume that data to the Bronze area tables for safekeeping. The landing layer is transient, and the data isn't kept there long. Bronze tables have the same structure as the data files received, but the format is kept as Delta in the background.
After the data is stored in the Bronze layer, we'll validate it, transform it, and store it in the Silver layer. The purpose is to keep the data modelled and normalised, allowing proper relational storage with easy discovery.
Let's begin by going through each of these data products.
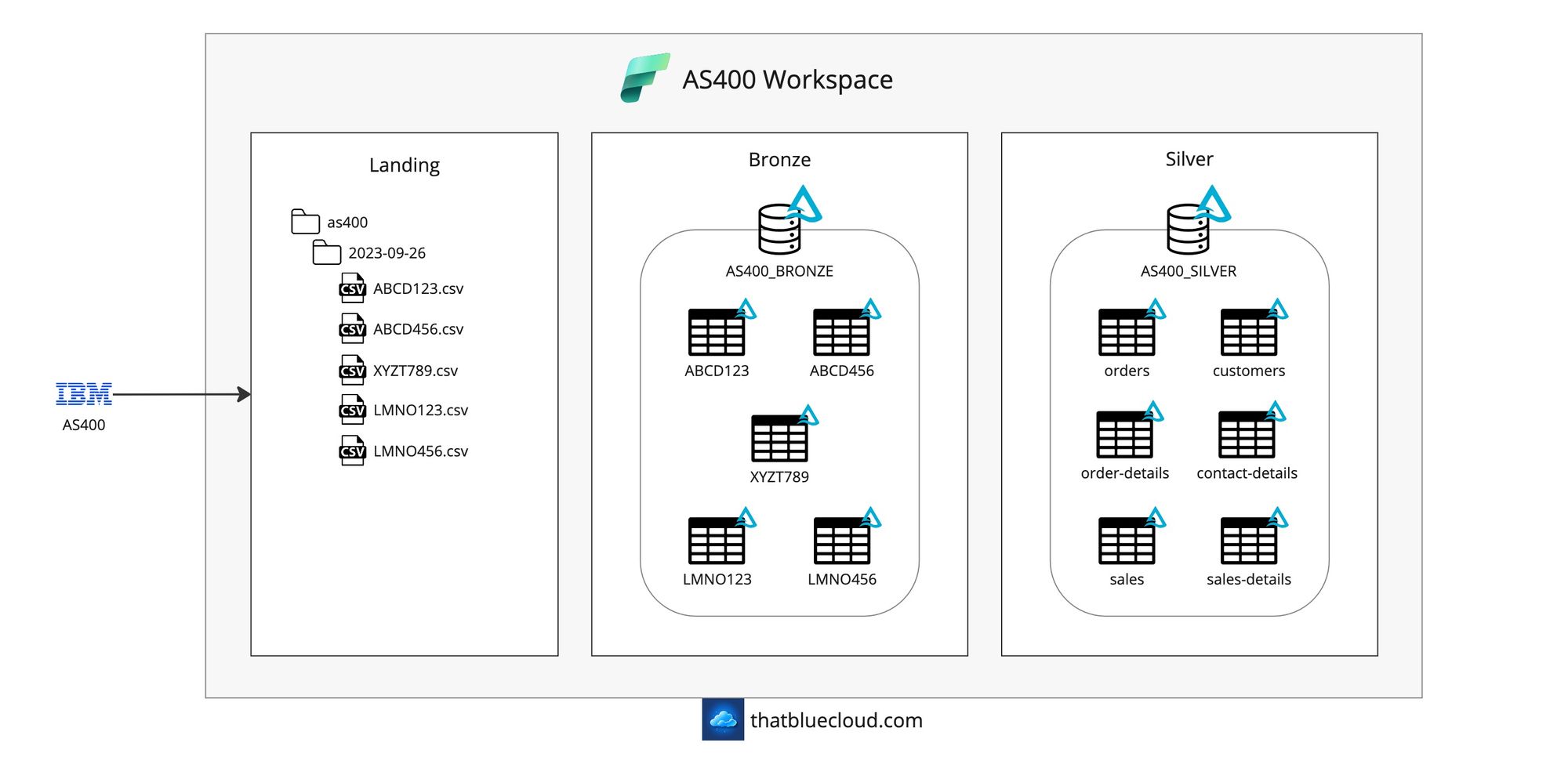
AS400
In most companies, AS400 is a primary system with extensive data and contains more than just orders, sales and customers. We're going to focus on just these three scenarios for simplicity. The data we're receiving from AS400 will be in five parts, and we'll query them directly from the DB2 database with scheduled overnight jobs.
- Vehicle Order (ABCD123 table)
- Vehicle Order Detail (ABCD456 table)
- Customer (XYZT789 table)
- Vehicle Sales (LMNO123 table)
- Vehicle Sales Detail (LMNO456 table)
AS400 is a system that comes with its hardware and runs a DB2 database in the background, which has strict limitations on the naming standards of columns and tables. We'll be retrieving the data in its original names into the Landing and Bronze layers, but we'll be transforming it into appropriately renamed and split tables in the Silver layer:
- Orders
- Order Details
- Customers
- Customer Contact Details
- Vehicle Sales
- Vehicle Sales Detail
DMS (Dealer Management System)
The retailers work on a franchise basis, so they have their own systems within their company. They operate using DMS (Dealer Management System) software with sales, service, spare parts, and customer modules. Dealers also use these systems to sell used cars (they use AS400 for new car sales).
Many software brands offer DMS products, and most retailers use customised versions of these products. There's no one-solution-fits-all here, and although parts of the system can be reused, we need to keep their data separately because of the customisations.
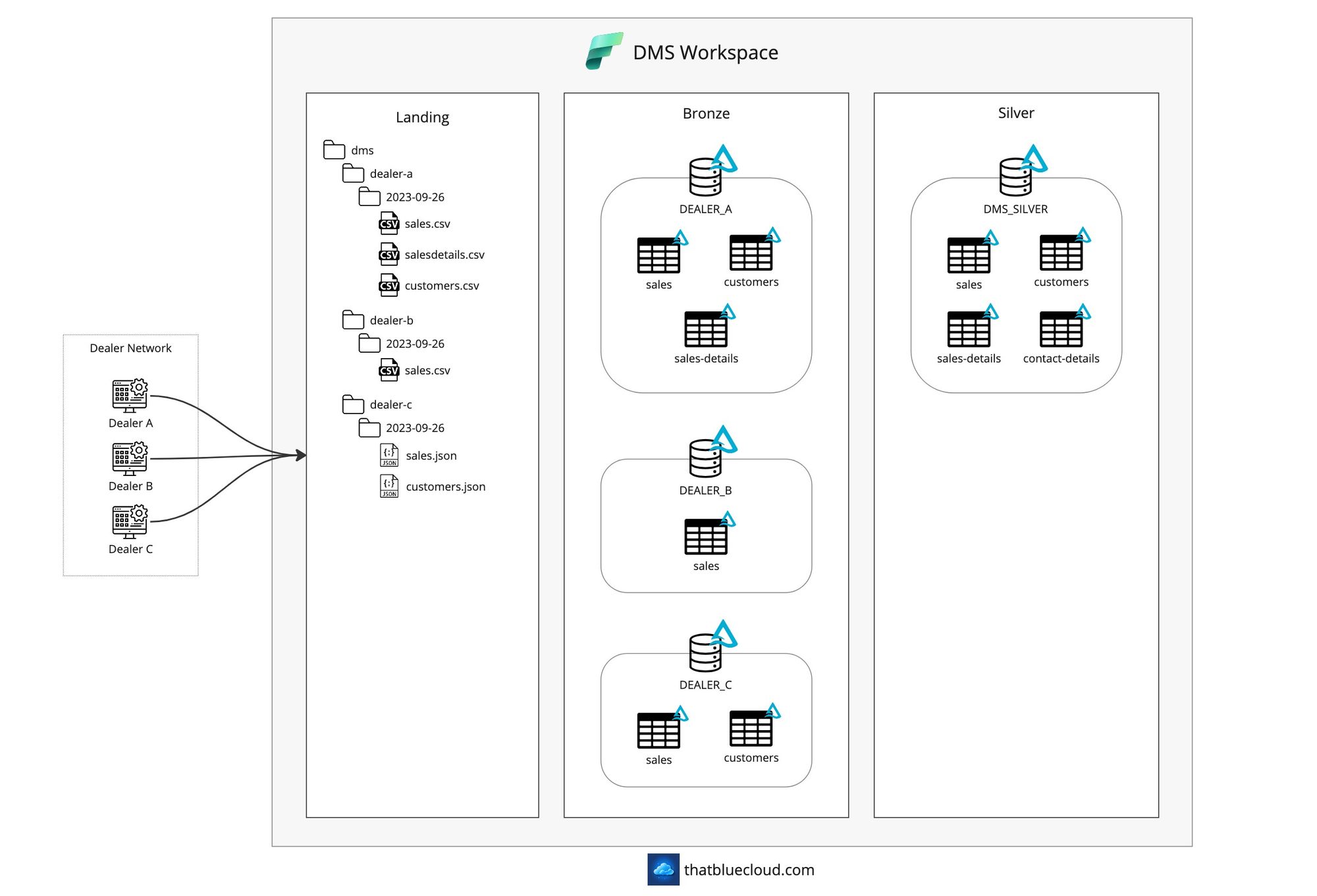
In our example, we include three different dealers/retailers to signify three different DMS brands. Each one uses a separate system, with the following files incoming to SFTP:
| Source System | Dataset | Format | Method | Frequency | Delta/Full |
|---|---|---|---|---|---|
| Dealer A | Used Vehicle Sales | CSV | Push | Daily | Delta |
| Used Vehicle Sales Details | CSV | Push | Daily | Delta | |
| Customer | CSV | Push | Daily | Delta | |
| Dealer B | Used Vehicle Sales | CSV | Push | Daily | Delta |
| Dealer C | Used Vehicle Sales | JSON | Push | Hourly | Delta |
| Customer | JSON | Push | Hourly | Delta |
Whilst we'll have three different Bronze layers for each dealer, we will have a single Silver layer that maps to all the retailers' data and consolidates them. You'll notice that Dealer C sends the data as hourly JSON files, which we'll store in Bronze immediately but won't import everything into Silver until the scheduled overnight time comes.
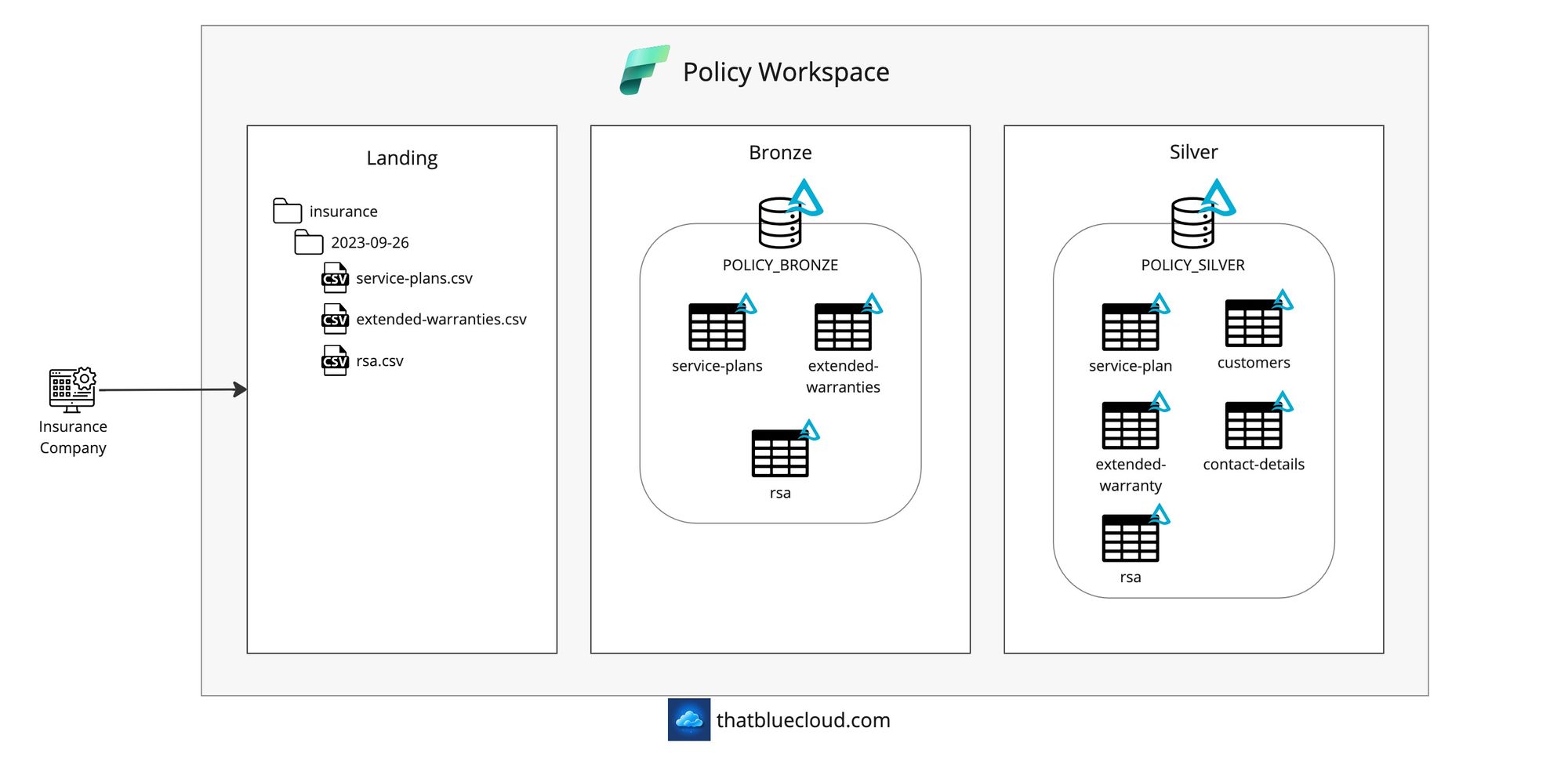
Insurance and Policies
Most automotive companies provide insurance for their customers, either short-term (driveaway insurance) or long-term (service plans, roadside assistance, extended warranty). Not all of these policies can be created through the same insurance company, and in most cases, more than one provider is involved. But for the sake of simplicity, we'll imagine we have a single insurance provider we're integrating with, which will be through the on-premise SFTP server.
We'll receive the insurance information overnight on the SFTP and ingest it into Fabric using the On-Premise Data Gateway.
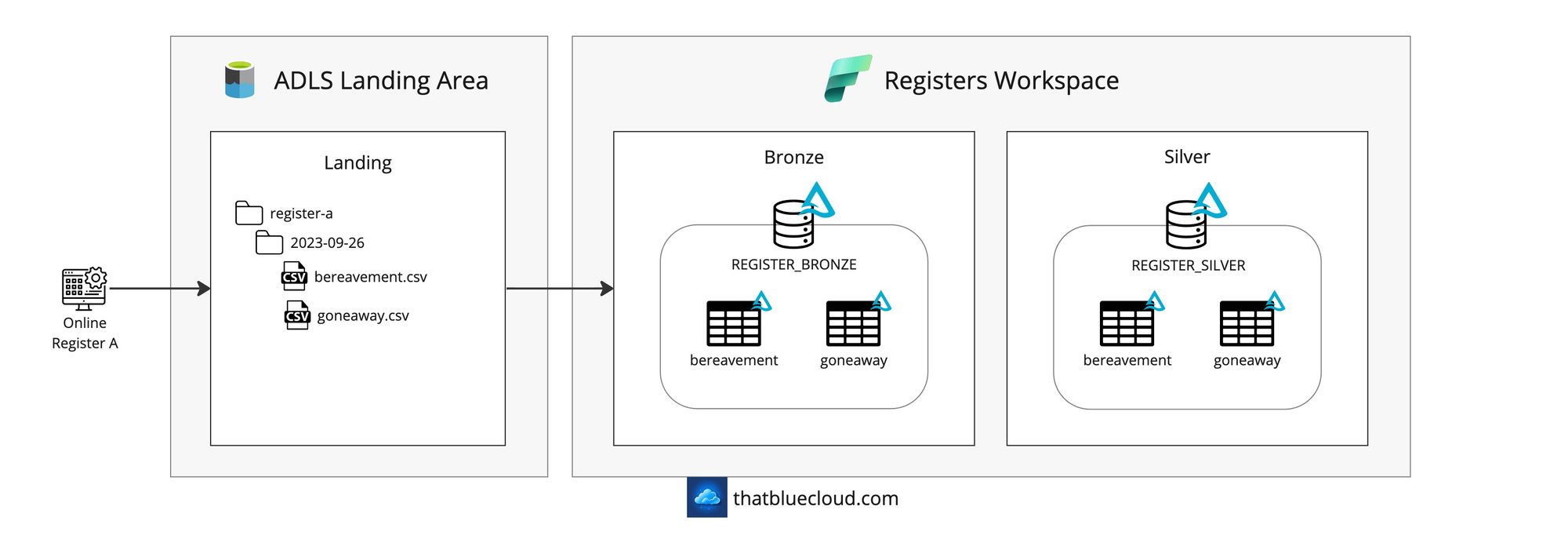
Online Registers
Many companies provide datasets you can use, and some of them you can integrate by sending your customer base and having them run sanity checks or enrich it with their data. Two of the (sadly) popular ones are Bereavement Registers and Goneaway Registers. You send your customer data to them, and they regularly scan and let you know if a particular customer is deceased or moved out of the country. This information is helpful if you're building marketing campaigns and don't want to send emails to people who are dead or moved away.
I didn't show the complete integration in the design, but their outputs are usually shared via SFTP. I've chosen an example where the Register company has the SFTP server in this instance so that it would be a pull from SFTP.
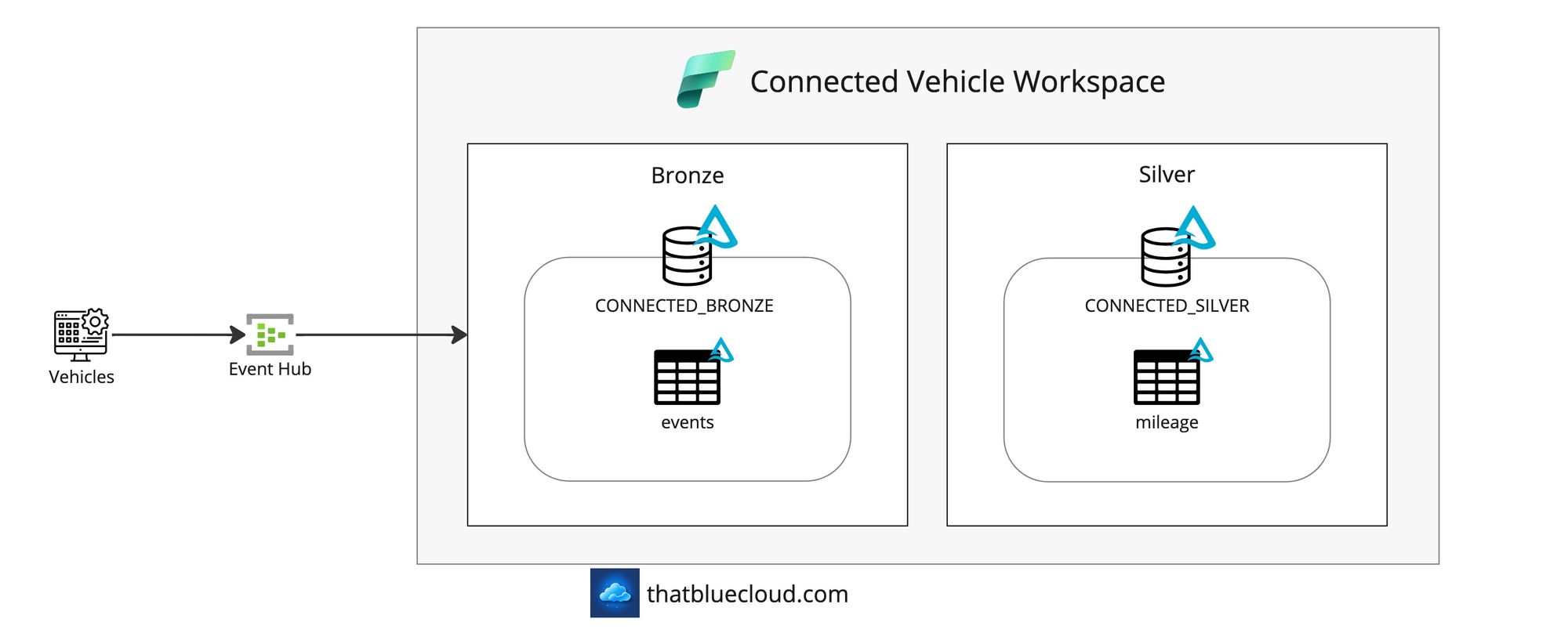
Connected Vehicles
In the new era of IoT, everything is connected to the Internet, even the cars. There are many reasons why a car would be connected: Roadside assistance, emergency services, anti-theft location tracking, etc., but we'll choose a basic example here: To receive car mileage every hour. It's not an exact use case, but rather than jumping into the world of personal data like location, it's a more straightforward use case where you might receive thousands of messages per second to demonstrate the streaming capabilities more lightly.
We'll imagine collecting the events coming from the cars into an Azure Event Hub, but we won't go into the details on how, as it's not really the use case here. We'll receive the events from the Event Hub and then process them into Bronze and Silver tables using Structured Streaming.
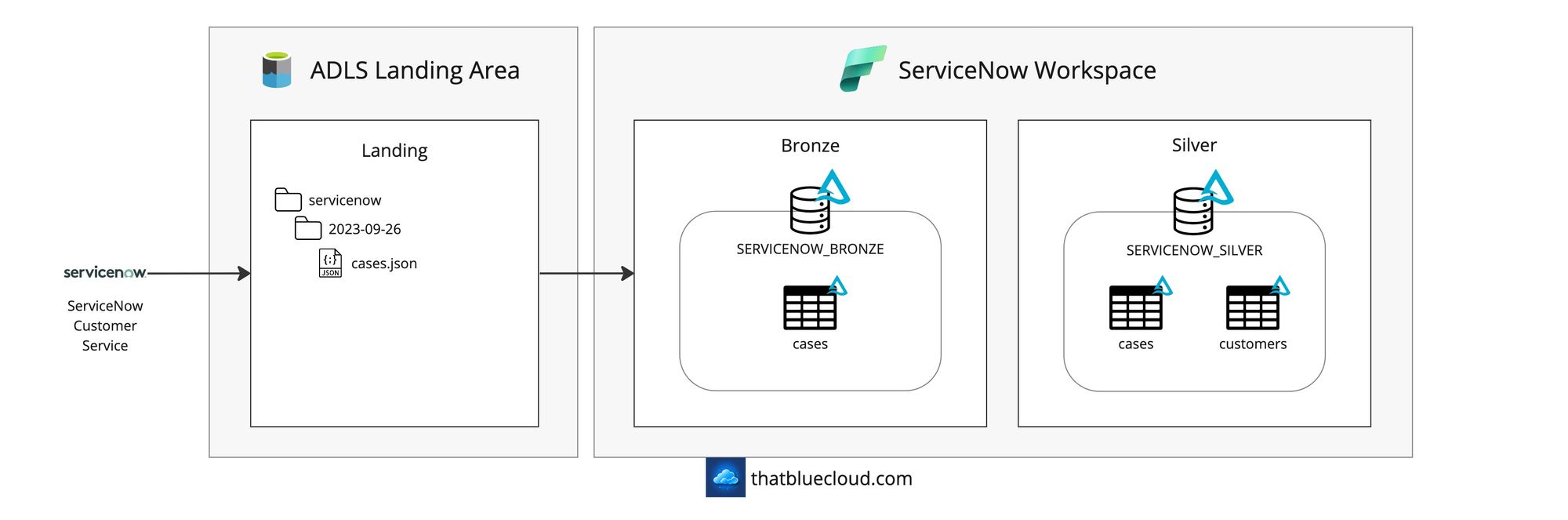
ServiceNow
I included ServiceNow to demonstrate a popular SaaS service connectivity in the picture and a use case where Fabric doesn't have a native connector, and it has to be supplemented with an Azure component, such as Azure Data Factory.
We'll use the ADF's ServiceNow connector to query the ServiceNow instance and then write into the storage account for Fabric to pick it up using the VNET Data Gateway.
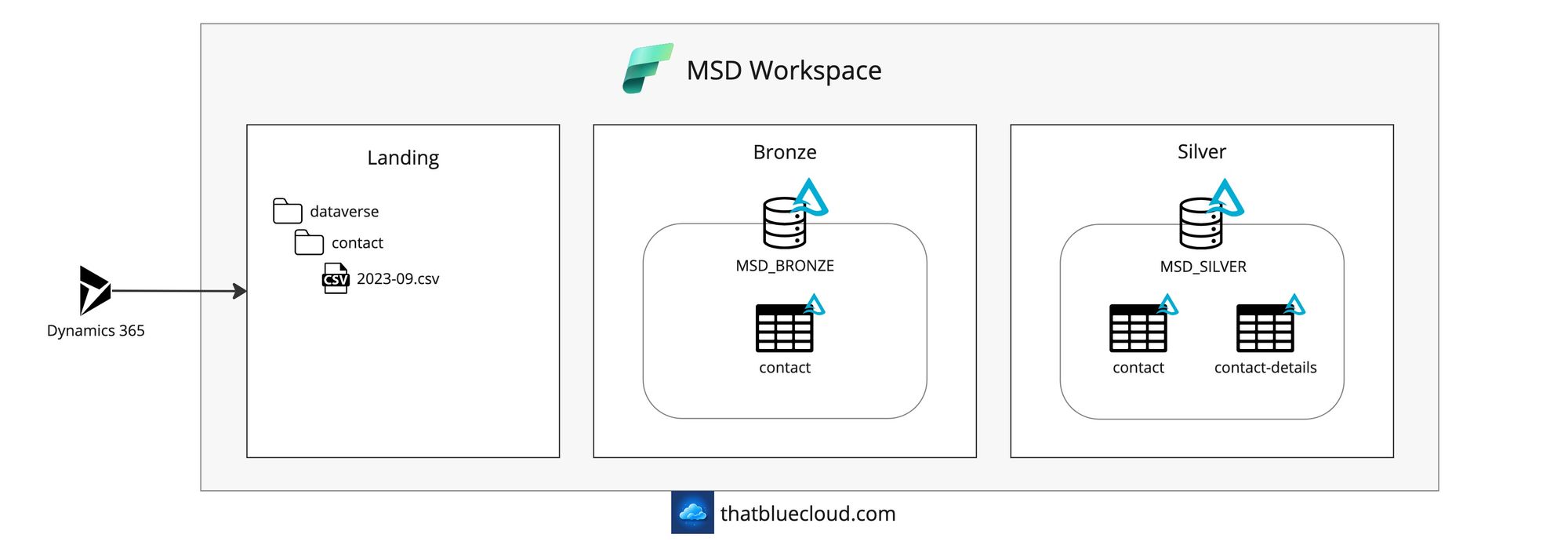
Microsoft Dynamics 365 and Dataverse
Microsoft Dynamics 365 uses Dataverse as its data storage, which has a capability called Synapse Link to publish the data to ADLS Gen2 and the Synapse Analytics Workspaces. Microsoft plans to release a new version of Synapse Link, which will start supporting Fabric as the destination for your data. This will allow the data to land onto a Fabric Workspace instead of a Synapse one and easily get the data ingested into the Bronze and Silver layers.
We'll only include a sample scenario here to prove our integration method viable, and that will be the Contact entity sent to the Fabric landing area. We'll query the incoming data using the last updated date and only receive the data that's been new or updated. We could implement it using Synapse Link's append-only mode, best reserved for more complicated scenarios.
Next article in the series:
 Harun Legoz
Harun Legoz
Previous article:
Harun Legoz
