

Articles in this design series:
- 1 - Introduction
- 2 - High-Level Design
- 3 - Trusted Data Products
- 4 - Gold Data Products
- 5 - Benefits & Drawbacks
Based on our main requirements, we'll be designing a solution on Microsoft Fabric with the capabilities it has in Preview. It comes with many benefits, but best of all, it has a unique closeness to the business ecosystem, which we want. We want to empower BI and citizen developers and derive more value from the data. We want the data engineering teams to focus on making the data available.
Let's start with the High-Level Design Diagram and talk about the components. Then, we'll look into how the data flows and other design aspects.
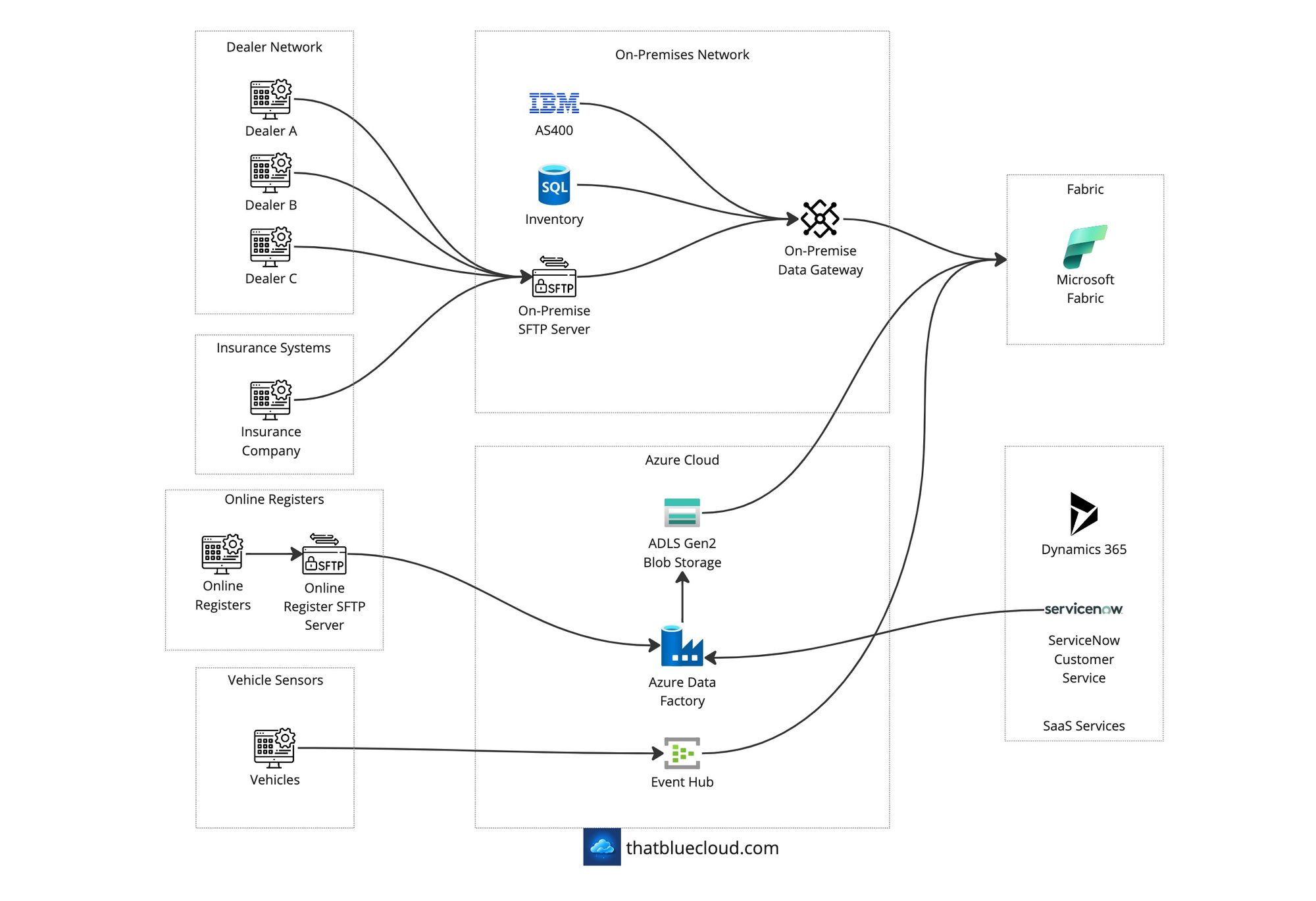
There are three major locations for data sources in our design:
- On-Premise: The company has its databases and apps hosted on-premise, including AS400 and its DB2 database. Additionally, the company hosts an SFTP server for its long-standing integrations with third parties, including the dealer network. This server acts as a drop zone for bi-directional integrations.
- Azure: After the expansion into Azure, the company started new apps on the cloud platform using the available tools. They have SQL databases, storage accounts, etc., with the data, but they also have an ADLS Gen2 account with an SFTP endpoint enabled for new integrations.
- Internet: There are several SaaS services the company uses, as well as other data sources, such as government data sources (DVLA records, MOT status, etc.) to pull from. We have two relevant authorities for our sample scenario: ServiceNow and Microsoft Dynamics 365.
There are four concerns when the source systems and their datasets are involved:
- Data Format: Some send the data as CSV, some as weird TSV or bar-separated, and some as JSON files.
- Frequency: Some sources send the data daily in the morning, some with overnight jobs, and some hourly. Near-realtime sources also send the data immediately when it's available.
- Access Method: The data access method differs from source to source. Whilst AS400 is a pull mechanism, the dealer network sends the data to SFTP hourly.
- Transfer Size: Some AS400 and dealer network datasets support delta sharing. Which means only the changed data is pushed. However, some datasets don't have change tracking or delta determination, only making complete data available.
You can find the complete list of sources, datasets & the four concerns we described above for each of them in the table below:
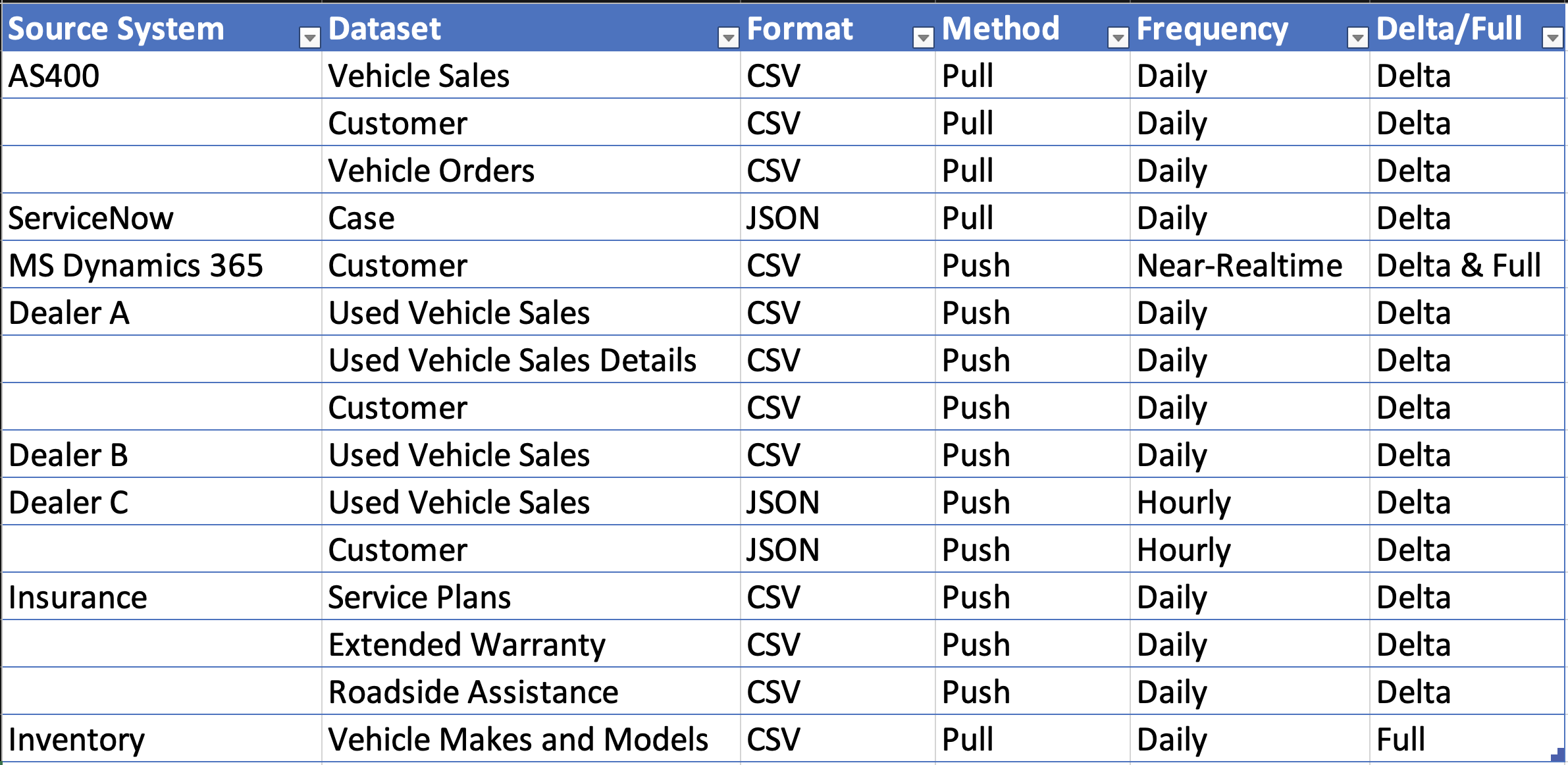
Source Systems and Datasets
Based on these requirements, the source systems we will be extracting the information from:
- AS400: An on-premise system that runs on DB2 database. The table names have character limits, so most of the time, they are difficult to pinpoint. The data must be queried from the database directly and sent to Azure for further processing.
- New Vehicle Orders
- Dealer Stock
- Vehicle Sales
- Customer Information
- Inventory: A SQL Server database hosted on-premise. Business units define vehicle makes, models and other reference data here via the UI so that it would be used by every app consistently.
- Vehicle Makes
- Vehicle Models
- DMS: Each dealer will be a different source, and there are a couple of DMS systems in the market that they use and customise. While the data models are similar, due to their different needs, each dealer has customised their system their own way. That means there won't be a single query we can develop and run on multiple systems. It needs to be adjusted per dealer and maintained.
- Used Vehicle Sales
- Customer Information
- ServiceNow: It's used extensively, but we'll mainly focus on the Customer Service part and extract the customer complaints/cases.
- Cases
- Customer Information
- Insurance System: The dealers can create insurance policies using various systems but assume a third-party insurance company is being used and bringing us insurance data. The insurance types are mainly grouped under the three below.
- Service Plans
- Extended Warranties
- Roadside Assistance
- Online Registers: Many third-party companies can provide you with different types of data. In our example, we'll imagine that we've integrated with a register to bring us a list of deceased customers. This is an essential aspect of customer data, as you wouldn't want to send marketing emails to people who are dead.
- Deceased Customers (Bereavement)
- Goneaway Customers (Moved out of the country)
- Connected Car: Vehicles are equipped with sensors to provide a connected car experience by sharing data with our company. We imagine we are receiving mileage data from the vehicle and stored on Azure. This will be our Streaming Dataset example.
- Vehicle Mileage
- Microsoft Dynamics 365: As our CRM, we'll use MS Dynamics 365 because it's a popular choice by many companies. It also will give us a near-realtime information use case and the demonstration of Synapse Link.
- Customer Information
Fabric Design
We have two alternatives here when designing our Fabric Workspaces, using the Medallion Architecture:
- Single Lakehouse: We can create a single Lakehouse with multiple schemas and put all the layers (Bronze, Silver, Gold) into it. This would make a unified data product, but it would reduce the reusability of the Bronze and Silver layers across the company, as they would become part of the product. Not reusable components. This is a monolithic approach, and it doesn't play well with our scenario. We must make the data available for future use cases and allow other data products to consume them.
- Multiple Lakehouses: We can create multiple data products and funnel the data from one to the other. OneLake allows us not to make copies of our data and reuse what's there to link one Lakehouse's data to another. This approach especially plays well when you would like to segregate the Gold products and make them lightweight, whilst Bronze and Silver layers are implemented once and pull the weight of making the data available. We'll be going with this approach.
I've written an article on "Designing Fabric Workspaces" and explained these approaches in great detail. I suggest you read the article, as I won't reiterate the same things here. But you can see from the diagram below how the structure is going to be:
 Harun Legoz
Harun Legoz
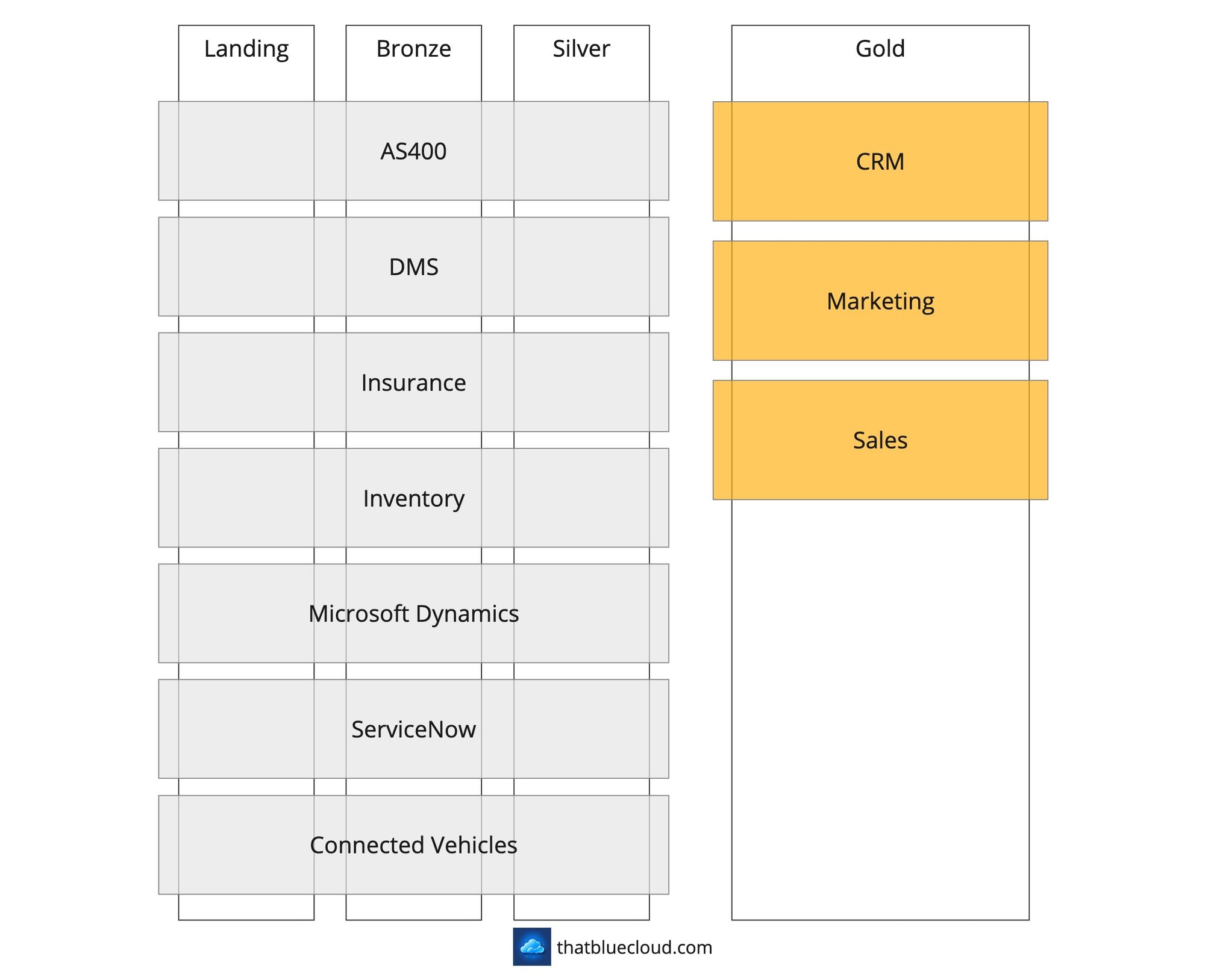
In the design, there would be two landing areas:
- Azure: We'll use an ADLS Gen2 storage to act as a Landing zone and welcome the data. We could binary copy the data into Fabric's Landing area from here, which would be redundant as this is not a long-term storage. It's a temporary customs area, and ADLS Gen2 has other capabilities that can be useful (SFTP support, SAS tokens, etc.).
- Fabric: This is embedded into the Trusted Product's Workspace to welcome the incoming data into OneLake. We'll use this when we don't need Azure, like pulling the data from the On-Premise SFTP Server or directly connecting to third-party SaaS services.
Authentication & Authorisation
Most communication methods will use Microsoft Entra ID (a.k.a. Azure AD) authentication whenever available. But not every communication method has Entra auth support. For example, the on-premise SFTP and the ADLS Gen2 SFTP endpoint have SSH-key authentication and don't support Entra auth.
The diagram below shows how the authentication & authorisation will work.
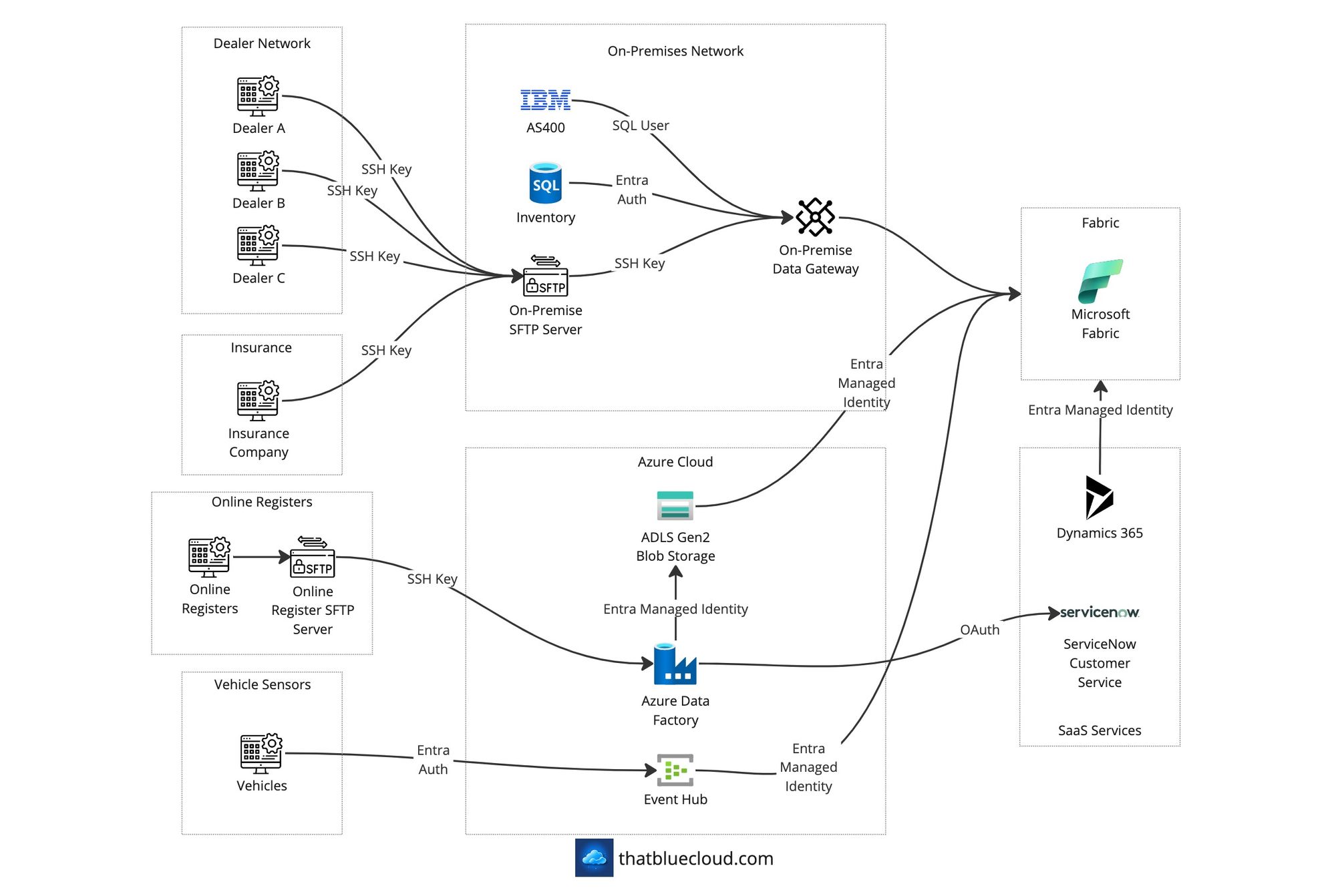
Network Design
The traffic comes to Fabric from three sources (On-Premise, Azure, and Internet).
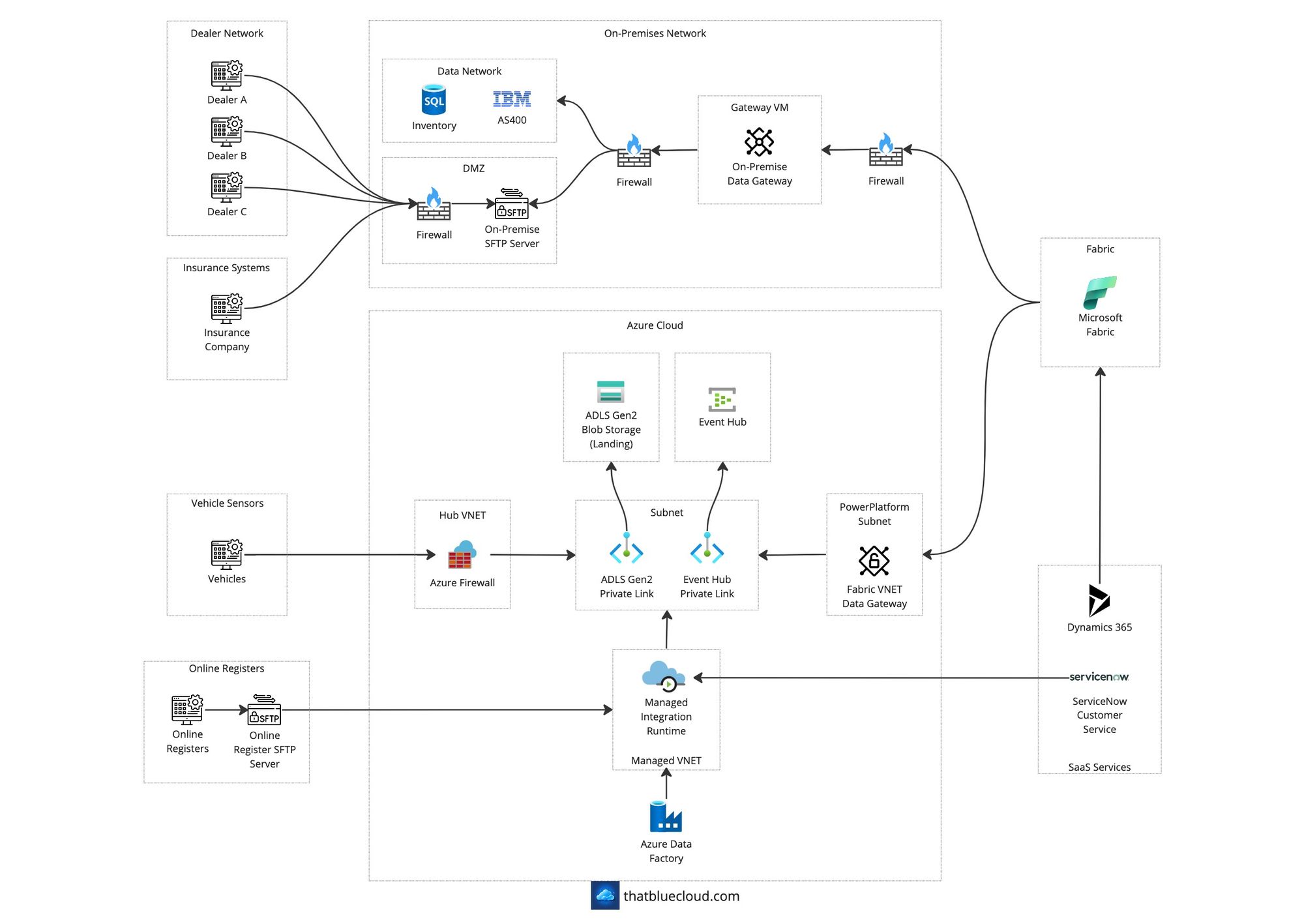
On-Premise
We're using the Power BI On-Premise Data Gateways to connect Fabric to On-Premise resources (AS400 and Inventory database). The Gateway is deployed as a VM into the company network, and it'll need access to:
- The databases via the internal firewall
- The on-premise SFTP Server via the internal firewall
- Outgoing Fabric access via the internal firewall
On the on-premise side, the dealer network talks to the company's on-premise hosted SFTP server, and the connection is limited to their incoming IP addresses on the firewall.
The same goes for the Insurance Company sending data via the on-premise hosted SFTP server.
Azure
In this example, we assume the company has an existing landing zone and a Hub & Spoke network architecture investment on Azure. The incoming traffic from Online Registers lands onto the Azure Firewall on the Hub, then forwarded to the ADLS Gen2's SFTP endpoint.
Similarly, the Sensor data collected from the vehicles would go through Azure Firewall and to the Event Hub's private endpoint.
Azure Data Factory would have a Managed Integration Runtime behind a Managed VNET, which would have access to private endpoints for resources. It would connect to ServiceNow via its designated connector and download the data onto ADLS Gen2.
We're using Fabric's VNET Data Gateway capability (which previously existed in Power BI) to access private endpoint-protected resources on Azure. It'll have access to both Event Hub and the ADLS Gen2.
Internet
Microsoft Dynamics 365 has a Fabric connector allows the data to land into OneLake directly. It's the Synapse Link connector we're used to from Synapse Analytics, and the data is automatically synced to OneLake. Instead of API connectivity, this would enable us to have historical data at our whim and allow us to process more data without the limitations of API connections.
Next article in the series:
Harun Legoz
Previous article:
Harun Legoz
